GMP调度模型演进
线程、进程切换
最初的操作系统是单进程的,及多个进程排队执行。在这种情况,若遇到前序进程因为某些原因阻塞,则后面的进程长时间获取不到时间片,则会陷于饥饿状态。后面人们为了解决这个问题,就涉及许多调度算法,例如多级轮转队列等,来让不同的进程抢占时间片。但后面人们发现,不同进程之间的切换成本太高了(需要保存寄存器地址,和栈现场等)。于是线程概念由此诞生。
相较于进程,线程有着更小的栈内存,这意味着创建、切换和销毁成本更低。但是由于线程的切换还是发生在内核态,仍然需要内核调用,切换成本包含:
1)一个内核线程的大小通常达到1M,因为需要分配内存来存放用户栈和内核栈的数据;
2)在一个线程执行系统调用(发生 IO 事件如网络请求或读写文件)不占用 CPU 时,需要及时让出 CPU,交给其他线程执行,这时会发生线程之间的切换;
3)线程在 CPU 上进行切换时,需要保持当前线程的上下文,将待执行的线程的上下文恢复到寄存器中,还需要向操作系统内核申请资源;
在高并发的情况下,大量线程的创建、使用、切换、销毁会占用大量的内存,并浪费较多的 CPU 时间在非工作任务的执行上,导致程序并发处理事务的能力降低。
用户态线程(用户态协程)
为了解决传统内核级的线程的创建、切换、销毁开销较大的问题,Go 语言将线程分为了两种类型:内核级线程 M (Machine),轻量级的用户态的协程 Goroutine,至此,Go 语言调度器的三个核心概念出现了两个:
M: Machine的缩写,代表了内核线程 OS Thread,CPU调度的基本单元;
G: Goroutine的缩写,用户态、轻量级的协程,一个 G 代表了对一段需要被执行的 Go 语言程序的封装;每个 Goroutine 都有自己独立的栈存放自己程序的运行状态;分配的栈大小 2KB,可以按需扩缩容;
在早期,Go 将传统线程拆分为了 M 和 G 之后,为了充分利用轻量级的 G 的低内存占用、低切换开销的优点,会在当前一个M上绑定多个 G,某个正在运行中的 G 执行完成后,Go 调度器会将该 G 切换走,将其他可以运行的 G 放入 M 上执行,这时一个 Go 程序中只有一个 M 线程:
这个方案的优点是用户态的 G 可以快速切换,不会陷入内核态,缺点是每个 Go 程序都用不了硬件的多核加速能力,并且 G 阻塞会导致跟 G 绑定的 M 阻塞,其他 G 也用不了 M 去执行自己的程序了。
为了解决这些不足,Go 后来快速上线了多线程调度器: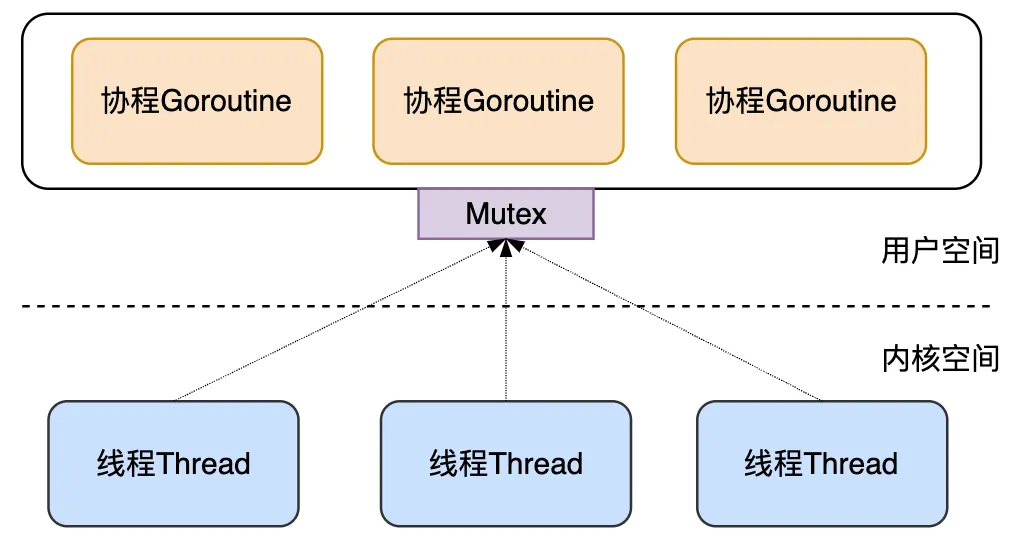
每个Go程序,都有多个 M 线程对应多个 G 协程,该方案有以下缺点:
1)全局锁、中心化状态带来的锁竞争导致的性能下降;
2)M 会频繁交接 G,导致额外开销、性能下降;每个 M 都得能执行任意的 runnable 状态的 G;
3)每个 M 都需要处理内存缓存,导致大量的内存占用并影响数据局部性;
4)系统调用频繁阻塞和解除阻塞正在运行的线程,增加了额外开销;
最终GMP模型
为了解决多线程调度器的问题,Go 开发者 Dmitry Vyokov 在已有 G、M 的基础上,引入了 P 处理器,由此产生了当前 Go 中经典的 GMP 调度模型。
P:Processor的缩写,代表一个虚拟的处理器,它维护一个局部的可运行的 G 队列,可以通过 CAS 的方式无锁访问,工作线程 M 优先使用自己的局部运行队列中的 G,只有必要时才会去访问全局运行队列,这大大减少了锁冲突,提高了大量 G 的并发性。每个 G 要想真正运行起来,首先需要被分配一个 P。
下图是当前 Go 采用的 GMP 调度模型。可运行的 G 是通过处理器 P 和线程 M 绑定起来的,M 的执行是由操作系统调度器将 M 分配到 CPU 上实现的,Go 运行时调度器负责调度 G 到 M 上执行,主要在用户态运行,跟操作系统调度器在内核态运行相对应。
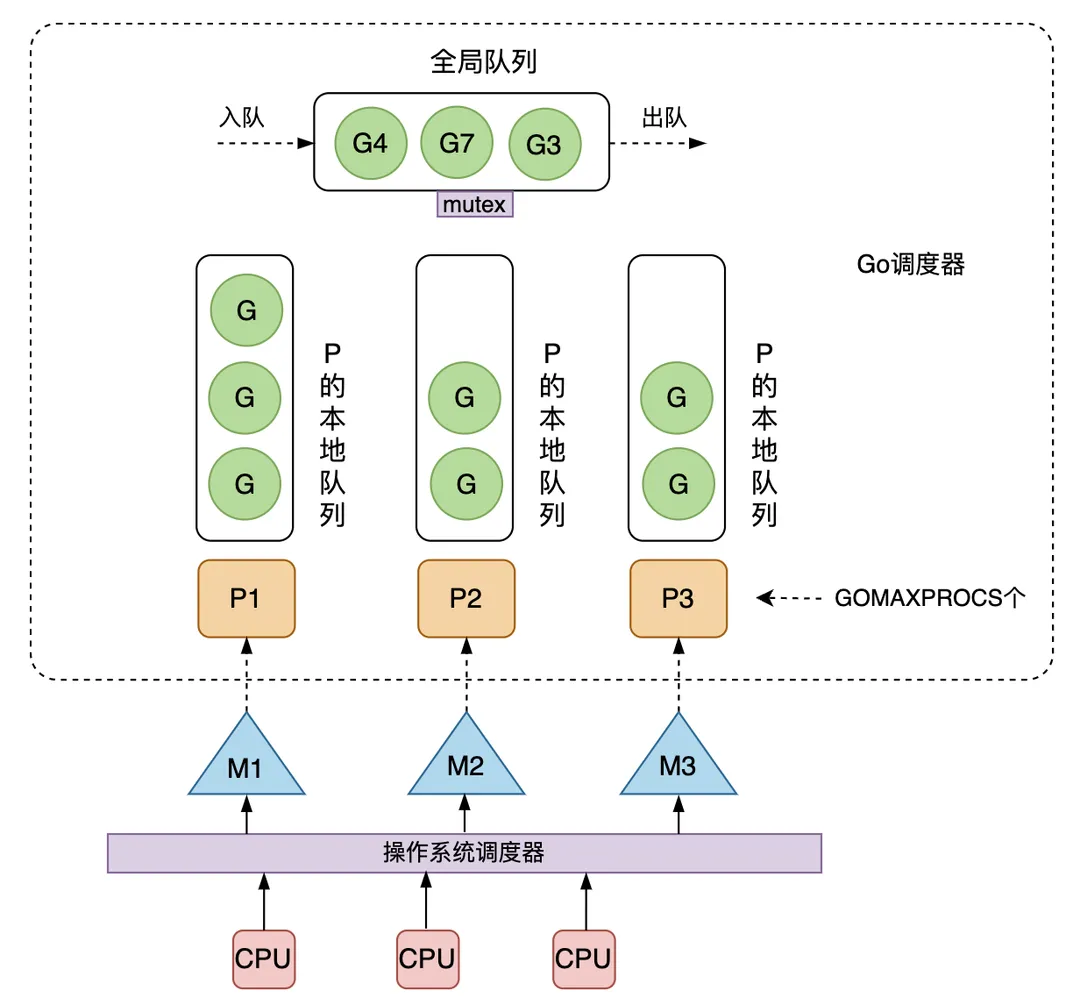
需要说明的是,Go 调度器也叫 Go 运行时调度器,或 Goroutine 调度器,指的是由运行时在用户态提供的多个函数组成的一种机制,目的是为了高效地调度 G 到 M上去执行。可以跟操作系统的调度器 OS Scheduler 对比来看,后者负责将 M 调度到 CPU 上运行。从操作系统层面来看,运行在用户态的 Go 程序只是一个请求和运行多个线程 M 的普通进程,操作系统不会直接跟上层的 G 打交道。
至于为什么不直接将本地队列放在 M 上、而是要放在 P 上呢? 这是因为当一个线程 M 阻塞(可能执行系统调用或 IO请求)的时候,可以将和它绑定的 P 上的 G 转移到其他线程 M 去执行,如果直接把可运行 G 组成的本地队列绑定到 M,则万一当前 M 阻塞,它拥有的 G 就不能给到其他 M 去执行了。
基于 GMP 模型的 Go 调度器的核心思想是:
尽可能复用线程 M:避免频繁的线程创建;
利用多核并行能力:限制同时运行(不包含阻塞)的 M 线程数为 N,N 等于 CPU 的核心数目,这里通过设置 P 处理器的个数为 GOMAXPROCS 来保证,GOMAXPROCS 一般为 CPU 核数,因为 M 和 P 是一一绑定的,没有找到 P 的 M 会放入空闲 M 列表,没有找到 M 的 P 也会放入空闲 P 列表;
Work Stealing 任务窃取机制:M 优先执行其所绑定的 P 的本地队列的 G,如果本地队列为空,可以从全局队列获取 G 运行,也可以从其他 M 偷取 G 来运行;为了提高并发执行的效率,M 可以从其他 M 绑定的 P 的运行队列偷取 G 执行,这种 GMP 调度模型也叫任务窃取调度模型,这里,任务就是指 G;
Hand Off 交接机制:M 阻塞,会将 M 上 P 的运行队列交给其他 M 执行,交接效率要高,才能提高 Go 程序整体的并发度;
基于协作的抢占机制:每个真正运行的G,如果不被打断,将会一直运行下去,为了保证公平,防止新创建的 G 一直获取不到 M 执行造成饥饿问题,Go 程序会保证每个 G 运行10ms 就要让出 M,交给其他 G 去执行;
基于信号的真抢占机制:尽管基于协作的抢占机制能够缓解长时间 GC 导致整个程序无法工作和大多数 Goroutine 饥饿问题,但是还是有部分情况下,Go调度器有无法被抢占的情况,例如,for 循环或者垃圾回收长时间占用线程,为了解决这些问题, Go1.14 引入了基于信号的抢占式调度机制,能够解决 GC 垃圾回收和栈扫描时存在的问题。
图解常见调度场景
创建G
正在 M1 上运行的P,有一个G1,通过go func() 创建 G2 后,由于局部性,G2优先放入P的本地队列;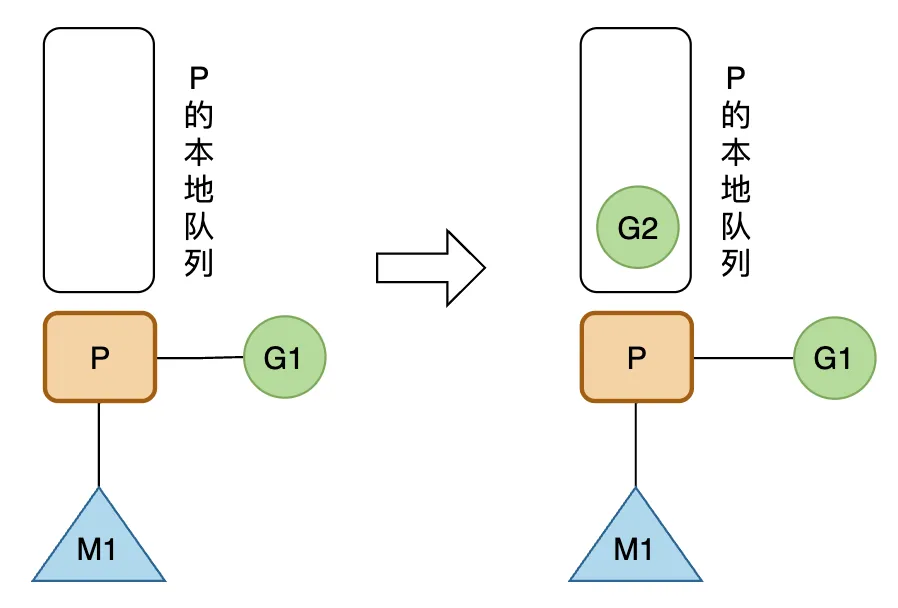
超过本地队列最大长度
如果 P 本地队列最多能存 4 个G(实际上是256个),正在 M1 上运行的 G2 要通过go func()创建 6 个G,那么,前 4 个G 放在 P 本地队列中,G2 创建了第 5 个 G(G7)时,P 本地队列中前一半和 G7 一起打乱顺序放入全局队列,P 本地队列剩下的 G 往前移动,G2 创建的第 6 个 G(G8)时,放入 P 本地队列中,因为还有空间;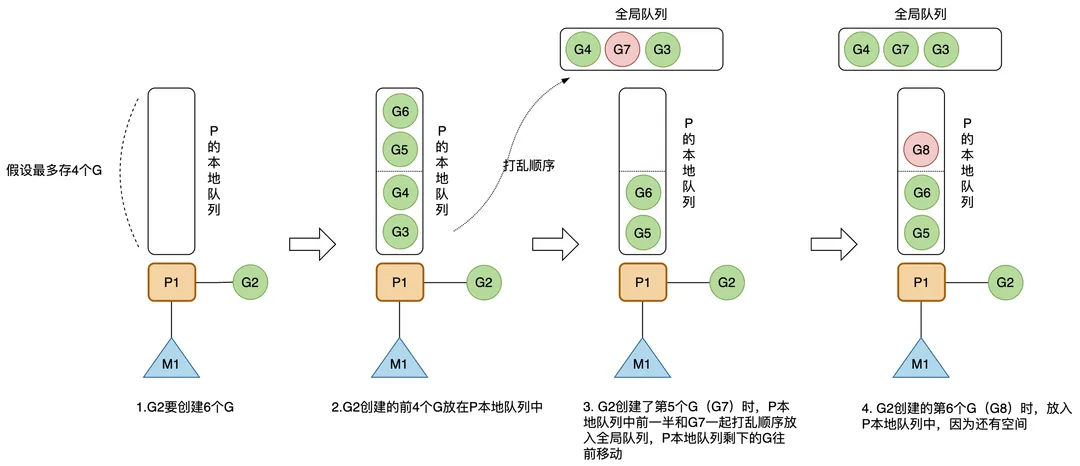
全局队列获取G
创建新的 G 时,运行的 G 会尝试唤醒其他空闲的 M 绑定 P 去执行,如果 G2 唤醒了M2,M2 绑定了一个 P2,会先运行 M2 的 G0,这时 M2 没有从 P2 的本地队列中找到 G,会进入自旋状态(spinning),自旋状态的 M2 会尝试从全局空闲线程队列里面获取 G,放到 P2 本地队列去执行,获取的数量满足公式:n = min(len(globrunqsize)/GOMAXPROCS + 1, len(localrunsize/2)),含义是每个P应该从全局队列承担的 G 数量,为了提高效率,不能太多,要给其他 P 留点;
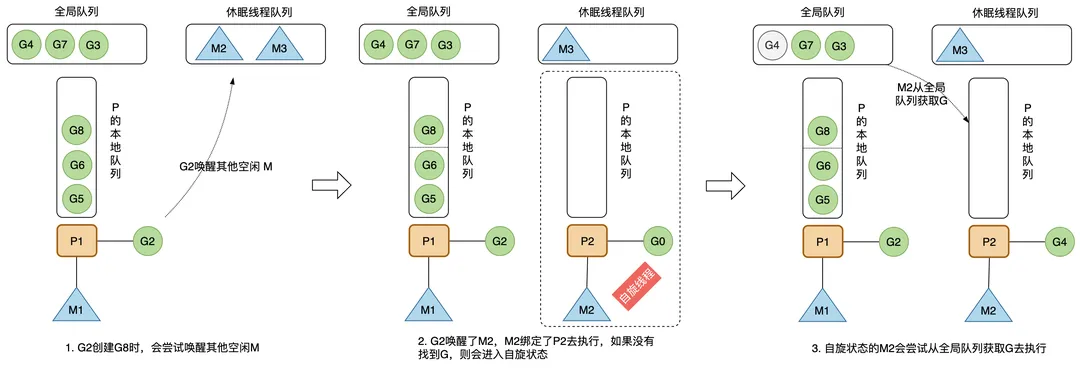
局部队列获取G
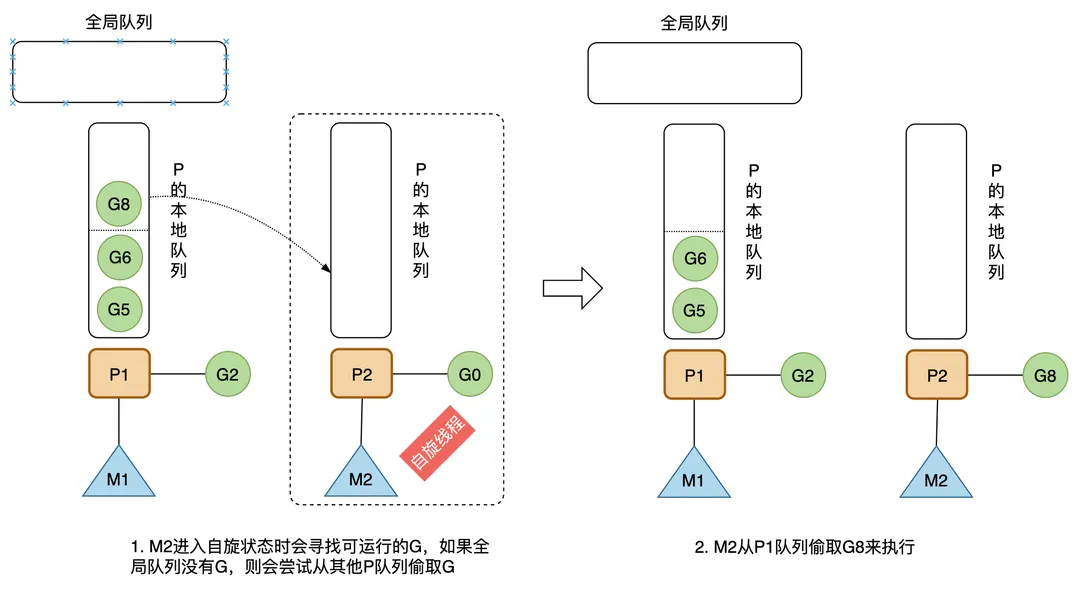
自旋状态的 M 会寻找可运行的 G。M优先从全局队列中寻找,如果全局队列为空,则会从其他 P 偷取 G 来执行,个数是其他 P 运行队列的一半;
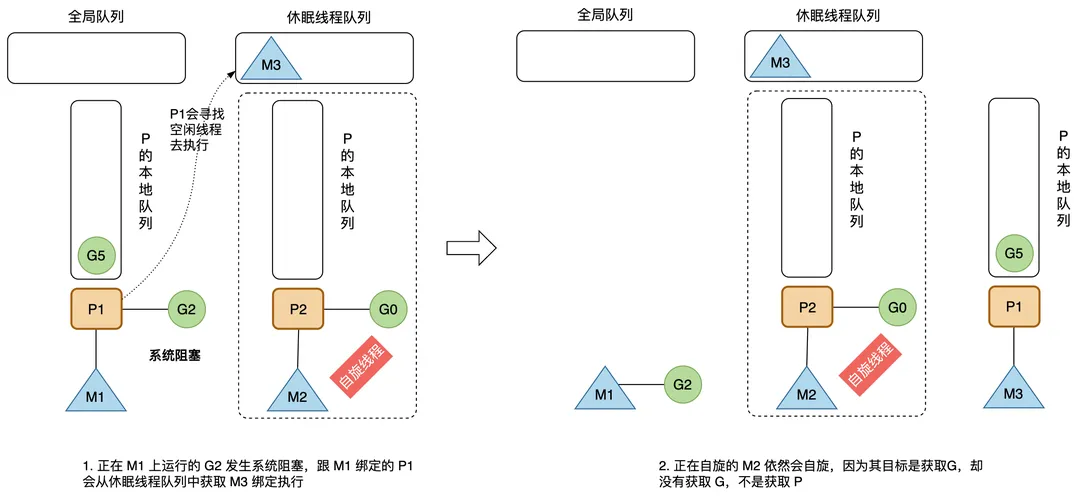
发生系统调用或者执行cgo
如果 G 发生系统调度或者执行cgo,其所在的 M 也会阻塞,因为会进入内核状态等待系统资源,和 M 绑定的 P 会寻找空闲的 M 执行,这是为了提高效率,不能让 P 本地队列的 G 因所在 M 进入阻塞状态而无法执行;需要说明的是,如果是 M 上的 G 进入 Channel 阻塞,则该 M 不会一起进入阻塞,因为 Channel 数据传输涉及内存拷贝,不涉及系统资源等待;
退出系统调用
如果刚才进入系统调用的 G2 解除了阻塞,其所在的 M1 会寻找 P 去执行,优先找原来的 P,发现没有找到,则其上的 G2 会进入全局队列,等其他 M 获取执行,M1 进入空闲队列;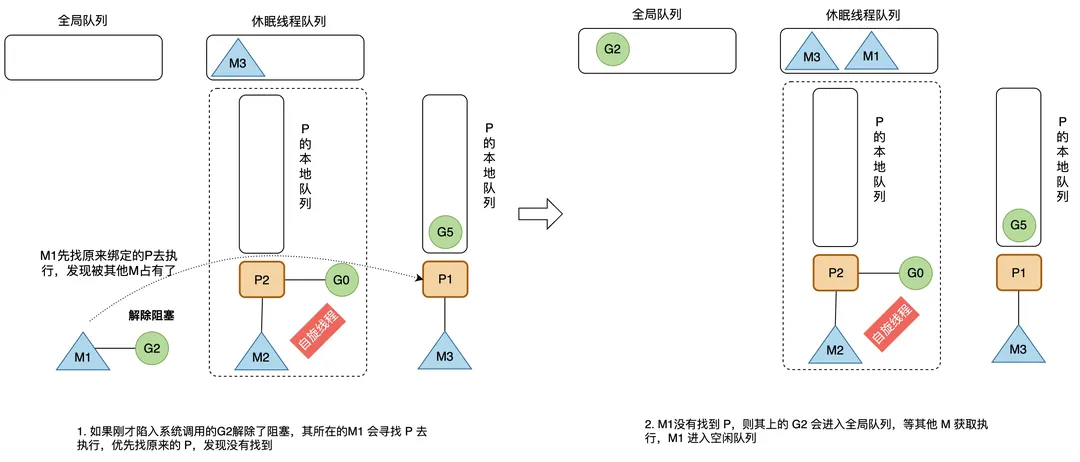
运行结束
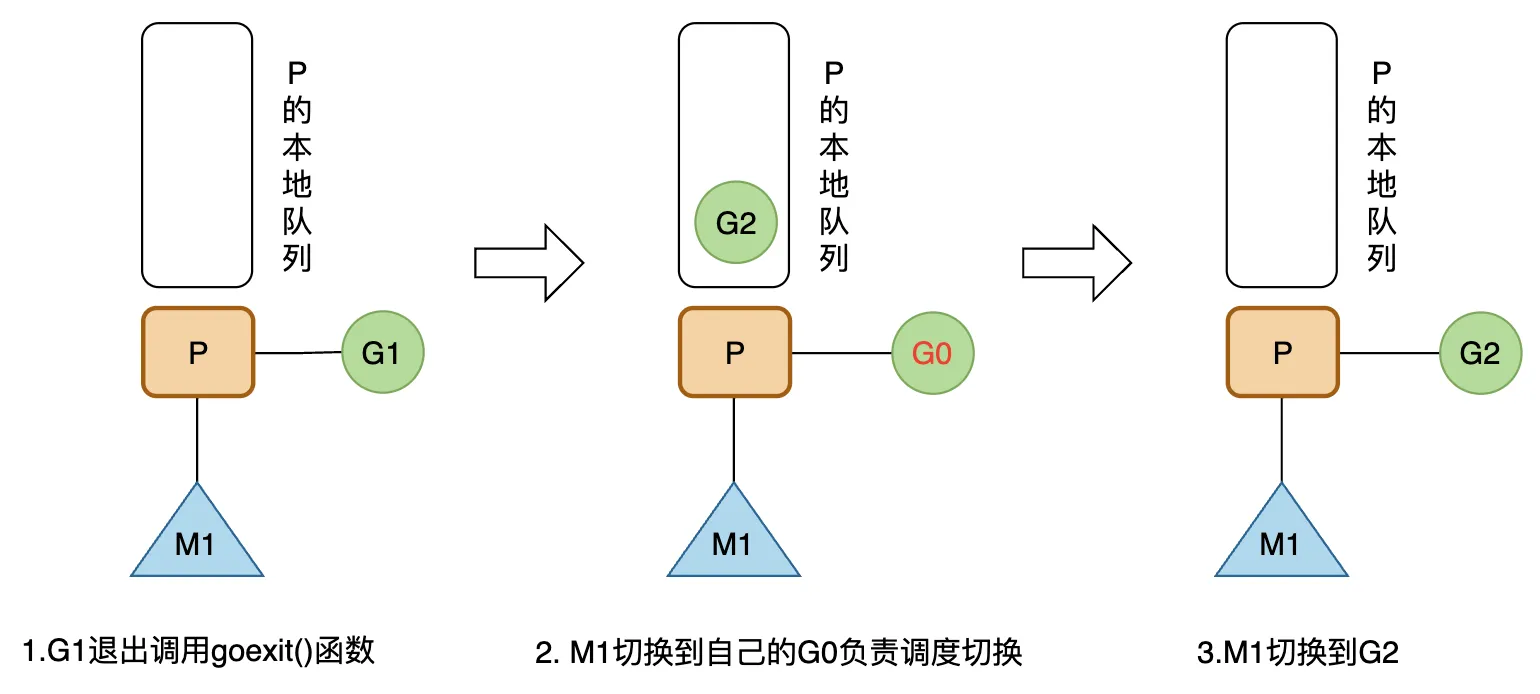
M1 上的 G1 运行完成后(调用goexit()函数),M1 上运行的 Goroutine 会切换为 G0,G0 负责调度协程的切换(运行schedule() 函数),从 M1 上 P 的本地运行队列获取 G2 去执行(函数execute());注意:这里 G0 是程序启动时的线程 M(也叫M0)的系统栈表示的 G 结构体,负责 M 上 G 的调度;