<论文阅读>Conditional Single-view Shape Generation for Multi-view Stereo Reconstruction
Contribution###
- 首次提出将单图重建工作中的模糊性进行建模。以单张图片作为输入,网络可以重建出若干符合单视角约束条件的三维模型。而这若干个三维模型就对单视角中的模糊性问题进行了建模,生成了模糊性空间。
Method###

Overview####
从上图可以看出,对于单图作为输入的重建模型,现有方法只能重建出一个确定的模型,而由于单图存在重建模糊性问题,肯定会导致该重建结果存在一些问题,特别是对不可见趋于的重建。而作者所提出的方法,可以在符合仅有的单视角约束条件下,重建出若干张图片,这些图片就模拟了不可见视角下的形状。
Single-view Reconstruction####
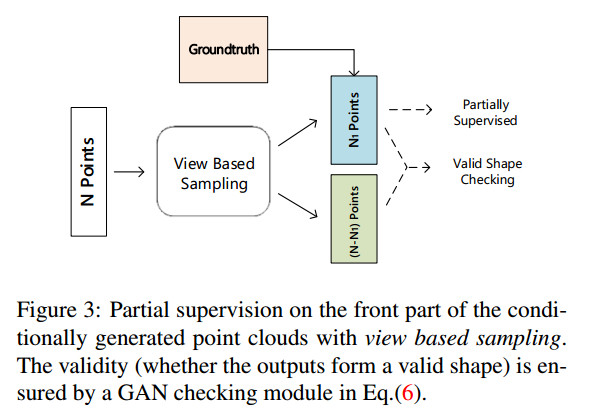
作者为了实现在重建的三维模型在符合单视角约束的前提下,对不可见视角进行合理猜想,设计了三个约束条件Front Constraint,Diversity Constraint,Latent Space Discriminator。
- Front Constraint
Front Constraint的作用是将收到视角约束限制的点从整个点云中分离开来。作者的做法是首先将重建得到的三维点云投影至二维平面以得到depth图片,然后再计算出哪些三维点构成了这些depth图片。文中将这些点的数量记为$N_i$
- Diversity Constraint
Diversity Constraint是限制剩下的$N-N_i$个生成点的位置。作者利用 $loss_{div}=max(0,||r_1-r_2||_2 - \alpha EMD(S_1,S_2))$ 来约束两个由同一张单视角图片生成的点云之间的差异性。$r_1,r_2$表示两个不同的随机向量,作者用这个来使得生成的模型具有一定的,可控的差异性。
- Latent Space Discriminator
Latent Space Discriminator被作者用来使生成的若干个三维模型不仅要符合单视角图片的约束,还需要符合一定的合理性。作者首先利用已有的点云表征学习的方法,训练了一个auto-encoder。接着作者将auto-encoder中的解码器移植到他自己的网络结构最后面,并将生成的三维模型作为输入,生成三维模型。
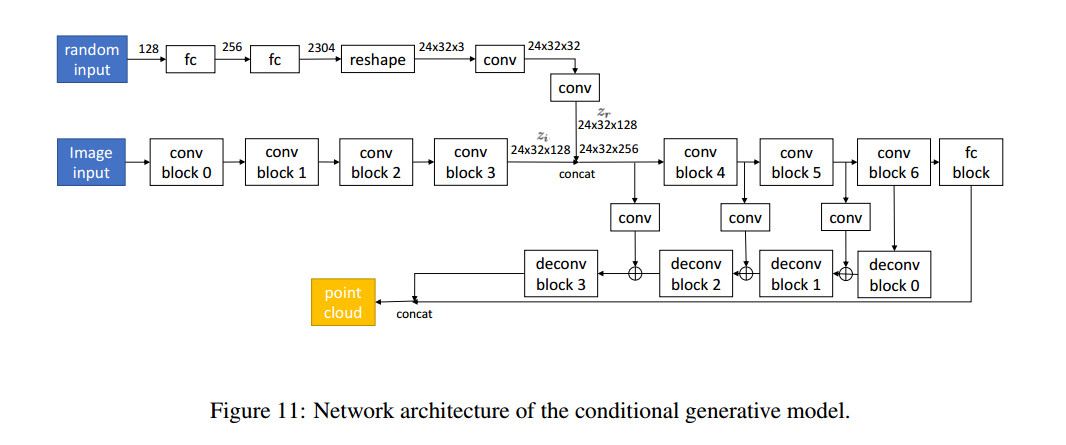
$loss_{gan} = - \mathbb E_{I_i \thicksim p_{data},r_i \thicksim p(r)}[D(E_I(I_i,r_i))] + \mathbb E_{S \thicksim P_{data}}[D(E_S(S))] -\lambda \mathbb E_{\hat z \thicksim p_{\hat z}}[(||\triangledown_{\hat z}D(\hat z)||_2)^2] \tag{1}$
其中$E_I$为作者自己网络的编码器,$E_S$为auto-encoder的编码器,$D$为判别器,$S$为从训练数据集中采样的三维模型。作者认为该结构可以学习到形状先验,以保证生成的三维模型的合理性
Synthesizing Multi-view Predictions
有了上面三个约束条件,作者预训练了一个单视角生成网络,但是网络的最终目的是生成一个准确的三维模型,这就需要用到多视角约束。
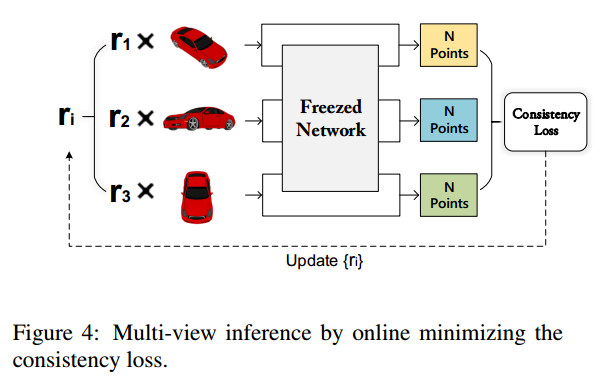
根据上图可知,输入有单视角图片扩展为多视角图片,然后为每个输入图片生成一个三维模型。接着根据 $loss_{consis} = \frac{2}{n(n-1)}\sum_{i=1}^{n-1}\sum^n_{j=i+1}CD(S_i,S_j)$ 来约束这几个三维模型的一致性。

根据算法步骤可以发现一个有意思的地方,作者称为heuristic search in initialization。作者首先随机选择5组不同和的${r_{ij}}^5_{j=1}$,每组包含的数量与输入图片数量一致。接着就分别把这5组$r_{ij}$结合同一组输入图片,输入到网络中,得到5个不同的$loss_{consis}$,把得到最小$loss_{consis}$的那组$r_{ij}$记为${r_i^+}{i=1}^n$。 接着在开始训练前,将预测模型Freeze,只根据loss值更新$r{ij}$,直到收敛。
Conclusion
1、将多视角重建问题分成两个部分,第一部分进行单输入图重建,并创造性的对固有的模糊性进行建模。作者对此在文中解释道:
However, different from the scenarios of generation in CGAN [27], we only have limited groundtruth (in fact, only one shape per image) which cannot span the reasonable shape space. We aim to learn a mapping to approximate the probabilistic model $p(S|I)$) in the reasonable shape space.
作者认为,单单靠一个监督是不足以使网络学习到一个可靠的形状空间。尽管作者做了消融实验证明了有效性,但是仍不足说服我。一个上百个点组成的三维空间,靠多预测个位数的三维模型,就能完成建模?)
2、作者采用的启发式初始化有一定的可取之处,让网络自身决定合适的初始参数是什么