<论文阅读>Learning View Priors for Single-view 3D Reconstruction
Contribution
- 提出了新的
视角先验方法,该方法弥补了对称先验的不足,虽然重建物体大多是符合对称先验的,但是在拍摄照片的那一瞬间,由于拍摄角度和物体本身发生的一些形变等原因,使得待重建的物体本身并不是对称,这样便会使得重建效果不佳。 - 提出了
internal pressure,即点可在与面片垂直的外方向尽可能膨胀。使得重建的物体更加饱满,看起来更加真实。
Methond
本文主要介绍其中的单图重建工作,方法可以很好的泛化为多图重建方法。
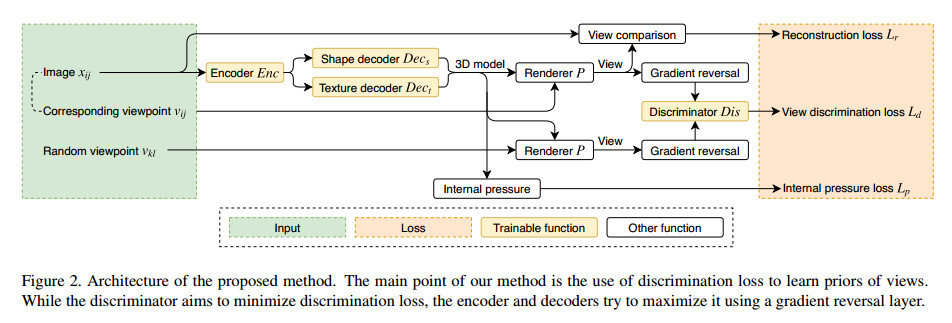
- View prior
其核心Loss函数为:
$\mathcal L_{r}(x,v) = \sum_{i=1}^{N_0} \mathcal L_{v}(P(R(x_{i1}),v_{i1}),x_{i1}) \tag{1}$
其中$R\left (* \right )$表示为重建函数,$P \left (* \right )$表示将重建好的三维物体按照$v_{i1}$视角投影会二维平面。而$\mathcal L_{v}$为衡量$x_{i1}$和$v_{i1}$视角下的重投影结果之间的误差(a function that measures the difference between two views)。
$\mathcal L_{s_1}(x_s,\hat x_s) = \sum_{i=1}^{N_s}\left( 1- \frac{x^i_s \cdot \hat x^i_s}{|x^i_s||\hat x^i_s|}\right) \tag{2}$
$\mathcal L_{s_2}(x_s,\hat x_s) = 1 - \frac{|x_s \bigodot \hat x_s|_1}{|x_s+\hat x_s + x_s \bigodot \hat x_s|_1} \tag{3}$
$\mathcal L_v = \mathcal L_s + \lambda_c \mathcal L_c \tag{4}$
其中$\mathcal L_c$为perceptual loss输入为RGB图片。$\mathcal L_s$的输入为剪影。$\mathcal L_{s_1}$是计算两个mask之间的余弦距离(可能是代表相似度??),作者使用了多尺度mask,$N_s$代表下采样的次数。 $\mathcal L_{s_2}$为IOU(intersection over union)函数,为的是约束其剪影尽可能重叠。正如上面的$\mathcal L_r(x,v)$所介绍的那也,以上的所有函数都是为了评价两张图片($x_s,\hat x_s$)之间的相似度,其中前者为ground-truth图片,后者为预测的图片。在此基础上,作者使用GAN网络来学习训练数据集中待重建物体不同视角的先验知识,而上面这个Loss函数是用来限制生成器的,根据原图和重投影图片之间的误差不同,来更新生成器的参数,以期获得更好的重建效果。
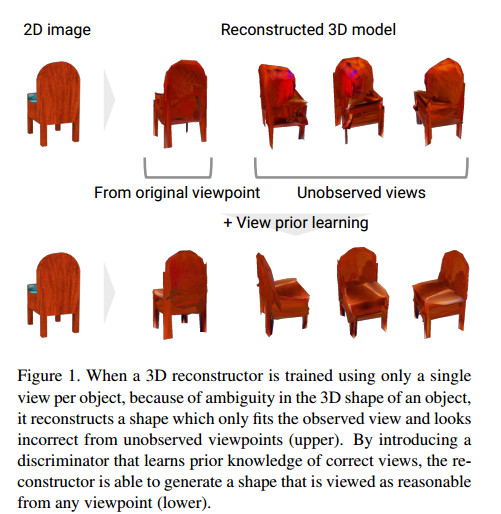
可以看到,对于椅子,使用作者提出视角先验的方法,重建的结果从各个视角看上去都更加符合实际情况。 基于这种情况,作者使用判别器来给生成器提供不同视角的重建信息。
$\mathcal L_d(x_{ij},v_{ij}) = -log(Dis(P(R(x_{ij}),v_{ij}),v_{ij}))-\sum_{v_u \in \mathcal V ,, v_u \neq v_{ij}} \frac{ log(1- Dis(P(R(x_{ij}),v_{u}),v_{u}))}{|\mathcal V -1|} \tag{5}$
整个网络的输入为单张RGB的图片,生成器首先依据图片重建出一个对应的三维模型,再根据这张图片所对应的相机视角反投影回二维平面,获得的图片可以记为$x_{gt}$。接着,在从$\mathcal V$中选取任一与之前的相机视角不一致的的相机视角,并依据此相机视角,再一次投影会二维平面。这是,第一次投影所得的$x_{gt}$就可以当做真实数据,第二次投影所得就可以当做加数据,一同送入判别器进行判断。作者在文中提到,所有的视角都是存在于训练集中的($\mathcal V$ be the set of all viewpoints in the training dataset)。这是否意味着对于一些在训练集中不存在的视角,该网络还是难以学习到其形状?
- Internal Pressure
这是一个较弱的先验知识,这个是受启发与Visual hull重建技术。通俗的来讲,就是使重建结果,在不改变投影误差的限制下,尽可能的朝着某个方向膨胀。作者采用的方法就是对每个点施加了一个沿着所在面片法向量的梯度(Concretely, we add a gradient along the normal of the face for each vertex of a triangle face. Let p i be one of the vertices of a triangle face, and n be the normal of the face)。为了实现这一效果,需要添加一个函数,该函数需要满足:
$\frac{\partial \mathcal L_{p}(p_i)}{\partial p_i} = -n \tag{6}$
即关于$p_i$点的偏导等于该点所在的面片的法向量$\overrightarrow n$。文中没有提及具体的函数选择。
Experiments

作者在文中提到,对于手机,沙发,飞机等物体。由于其形状单一,获取的多视角先验可以很好的解决在不可见视角下,重建效果差的问题。但是对于灯(lamp)这类物体,由于其形状的多样性,现有的网络并不能很好解决这个问题。