<论文阅读>Paper set: how to extract geometric features from spatial layout of points
- [1]TOG2018 Dynamic Graph CNN for Learning on Point Clouds
- [2]CVPR2018Mining Point Cloud Local Structures by Kernel Correlation and Graph Pooling
- [3]AAAI2019MeshNet: Mesh Neural Network for 3D Shape Representation
- [4]CVPR2019Structural Relational Reasoning of Point Clouds
- [5]CVPR2019Relation-Shape Convolutional Neural Network for Point Cloud Analysis
Dynamic Graph CNN for Learning on Point Clouds
Description:####
作者认为Pointnet和Pointnet++均只是探究了点云局部的独立的,本身的几何结构(Pointnet尽管是将一个完整点云分割为若干子点云来分别计算几何结构,但其还是处于local sacle的程度),并没有得到自己与其他点,其他子点云之间的关系。作者利用图神经网络在处理不规则数据上的优势,在抽取点云中各个点之间的几何关系,从而弥补了之前方法的不足
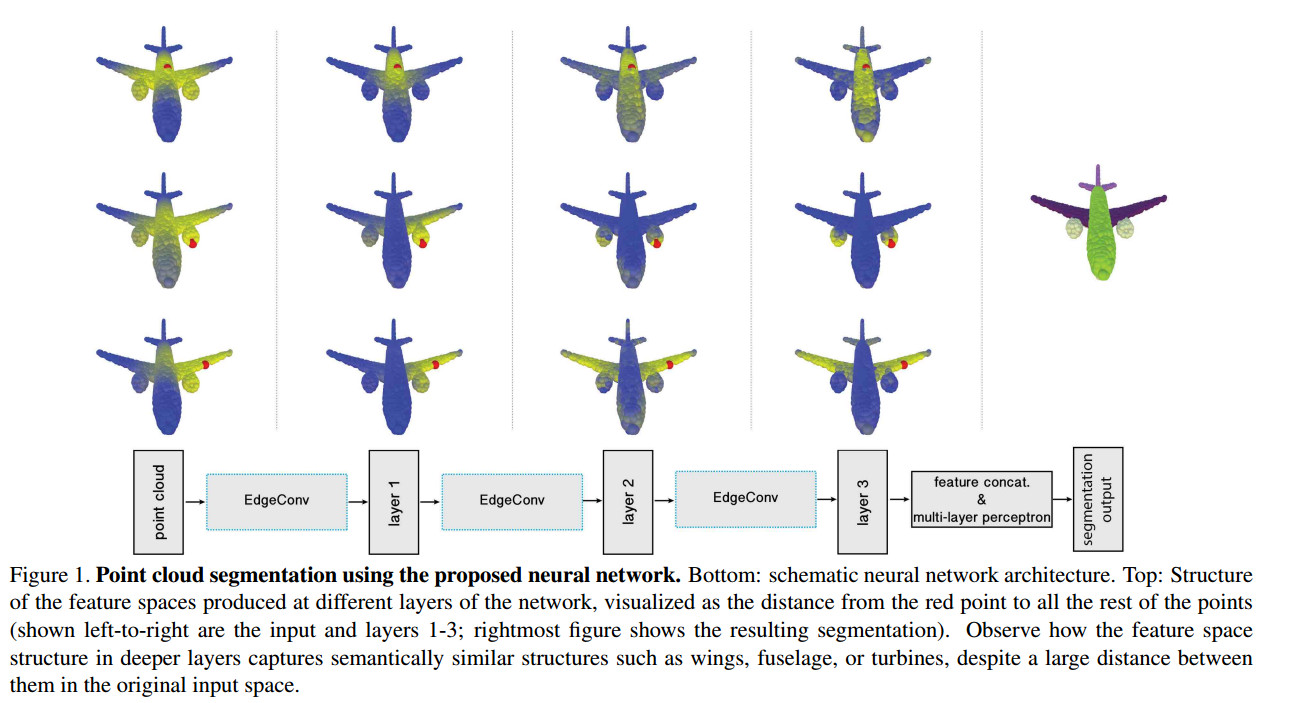
Contribution:####
作者提出了一种可以在点云处理中使用的操作:EdgeConv。并且通过大量的实验证明了改操作可以更好的在提取点云局部几何特征的同时保持排列不变性。
Method:####
作者在relate work->Geometric Deep learning中提到A key difficulty,however,is that the Laplacian eigenbasis is domain-dependent;thus, a filter learned on one shape may not generalize to others. 就是对于图卷积网络来说,基于频域的卷积其泛化性不如在空域中的卷积。
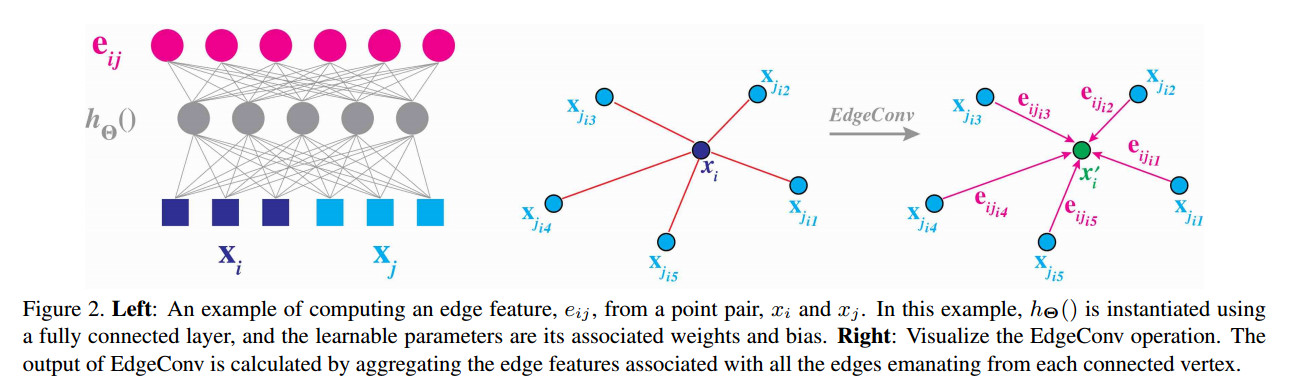
- EdgeConv
假设点云点数为N,同时每个点上的特征维度为F,那么就有$X = {x_{1},…,x_{n}} \subseteq R^{F}$ 。对于每个点上的特征向量的计算,选取在特征空间上与中心点最近的K近邻点(k-nearest neighbor) 表示为$\mathcal G = (\mathcal V, \varepsilon)$ 其中$\mathcal V={1,…,n }$代表点,$\varepsilon$表示中心点与其K近邻的边。那么EdgeConv的公式可以表示为:
$ x_{i}^{‘} = \square h_{\theta} (x_{i},x_{j})$ $s.t. j:(i,j) \in \varepsilon$ $x_{i}$表示在i th点上的特征向量
其中$\square$ 代表channel-wise的对称aggregation操作,例如叠加或求最大值(to keep permutaion invariance),每层EdgeConv对每个点$x_{i}$都会更新其特征向量
本文采用的Max Aggregation方法
Choice of $h_{\theta}$
- $h_{\theta}(x_{i},x_{j}) = \theta_{j}x_{j}$ 这就相当于普通的CNN卷积了,$x_{i}$就相当于卷积核中间的那个点,$x_{j}$是其周围的点,$\theta$是可学习参数
- $h_{\theta}(x_{i},x_{j}) =h_{\theta}(x_{i})$ 这就是
Pointnet的处理方式,只独立的考虑一个点 - $h_{\theta}(x_{i},x_{j}) =h_{\theta}(x_{i}-x_{j})$ 该方法作者认为只考虑了编码局部信息,失去了全局形状结构
- $h_{\theta}(x_{i},x_{j}) =h_{\theta}(x_{i},x_{i}-x_{j})$ 弥补了上一个方法的不足,也是本文所采取的方法
Dynamic graph update
在每一层EdgeConv之后,作者都会计算一个根据新得到的每个点的特征向量,计算一次KNN,并用这个新的KNN Graph来计算下一层的特征向量。
- Implementation
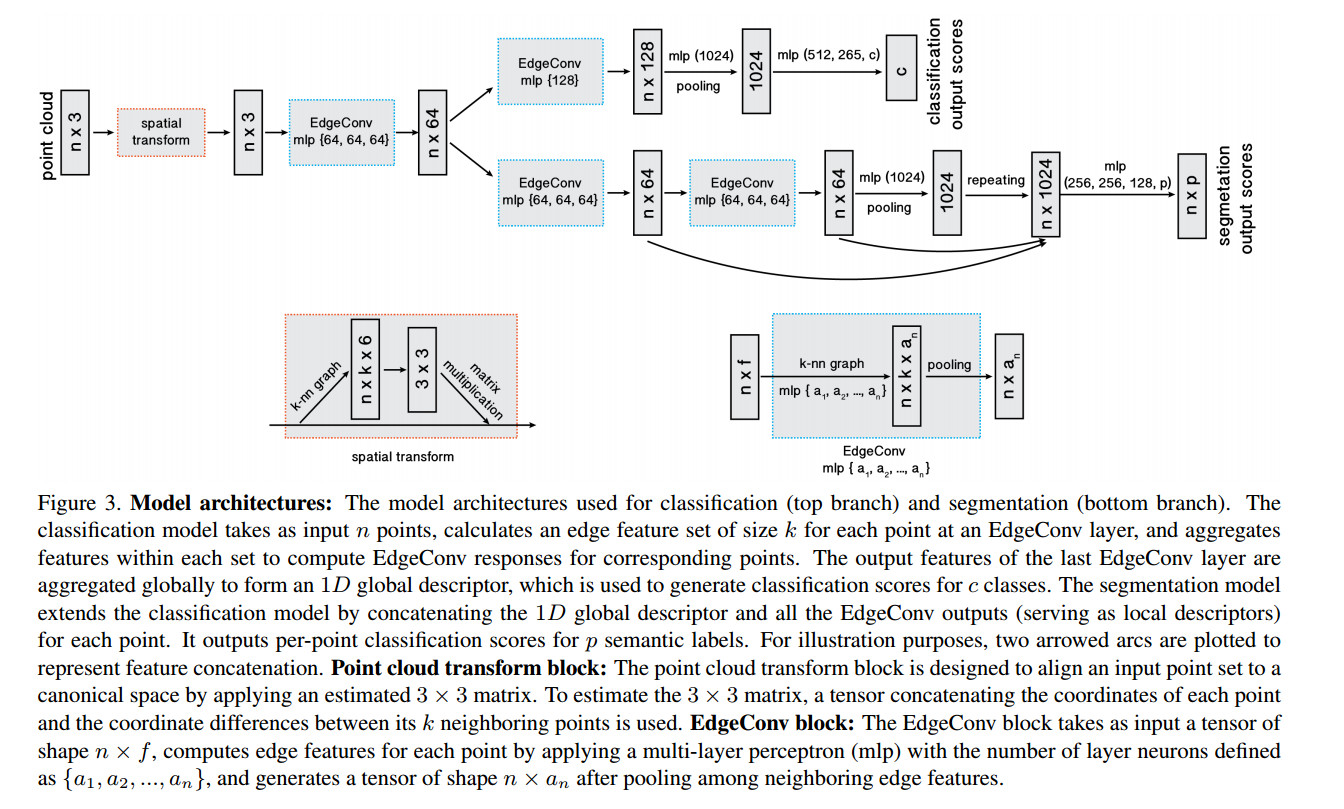
注意EdgeConv层的维度
- Experiment
首先当然是取得了state-of-art的成绩。有趣的,作者发现对于近邻K的选取,不是越大越好,对于不同的任务,都有一个峰值K使得效果最好,作者认为过大的K会使得欧式距离不能很好的估计测地距离(geodesic distace)会摧毁几何信息。同时作者发现K的选取跟点的密度有关
Mining Point Cloud Local Structures by Kernel Correlation and Graph Pooling
Description:###
这篇文章与[1]是同一时期的论文,但是在ModelNet40上的分类和ShapeNet上的分割都略微不如[1],但其思想是值得借鉴的。
作者利用在04年ECCV上的一篇关于point cloud registration工作上的技术kernel Correlation来对局部几何信息进行编码,可以理解为2D CNN中卷积核(kernel)的一种特殊的3D变种,其会对具有不同结构信息的点产生不同程度的响应(response)。同时作者也提出了一种利用K nearest neighbor graphs(KNNG)的新的特征聚合方法(feature aggregation)来利用高维结构特征推断集合信息。
Contribution:####
作者提出了借用kernel correlation的思想来简化求解local structural feature
Method:####
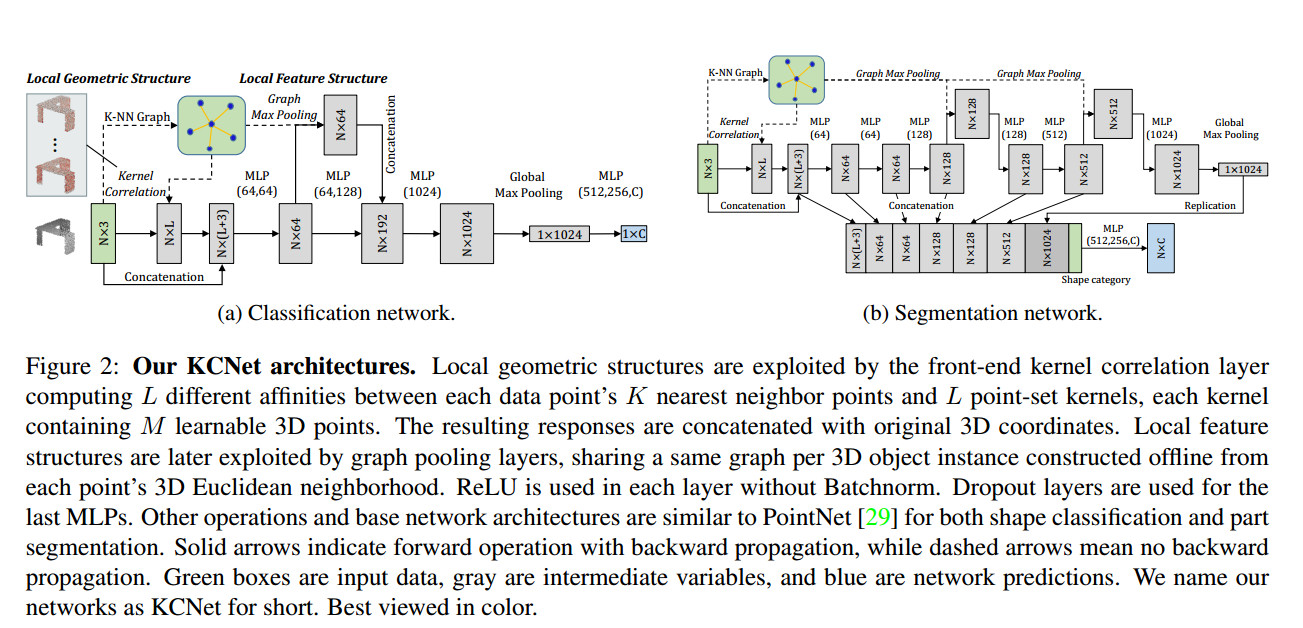
Local Geometric Properties
- Surface Normal: 作者在论文中提到可以用PCA求解的minimum variance direction作为局部的法向量,原话是:
surface normal can be estimated by principal component analysis on data covariance matrix of neighboring points as the minimum variance direction - Covariance Matrix(协方差矩阵): 作为二阶局部描述子,它能提供比normal更加多的信息量。但是作者认为
normal与Covariance Matrix作为手工设定的特征,其描述局部结构特征的能力有限,因为不同形状的几何结构可能产生相似的normal或者covariance matrix,这就给后续工作带来巨大的噪音。 - Kernel Correlation:
Kernel Correlation可以帮助用来判断两个Point cloud之间的相似度(similarity)。在point cloud registraion当中,一个point cloud作为reference,另一个作为source。source要不断的进行刚性/非刚性变换以使得kernel correlation的响应达到最大。也就是说,响应大的时候,两者的几何结构是非常相似的,那么这种性质就可以用来构造卷积核。
- Surface Normal: 作者在论文中提到可以用PCA求解的minimum variance direction作为局部的法向量,原话是:
Learning on Local Geometric Structure
point cloud registration 中的kernel corelation是固定一个template(reference),试图找到一个变换(transformation)使得source+transformation的结果与refrence的响应最大。而本文作者对此进行了改进,在整个训练过程中,template(reference)不再被固定,而是通过反传误差,不断学习到一个合适的reference(这里可以看成不断调整初始reference中点的位置),从而使reference与source的响应达到一个水准,这个水准能与网络其余结构一起产生预期的预测效果。论文原话是:
Under this setting, the learning process can be viewed as finding a
set of reference/template points encoding the most effective and
useful local geometric structures that lead to the best learning
performance jointly with other parameters in the network.
kernel corelation的计算公式:
$KC(\mathcal k,x_{i} ) = \cfrac{1}{\mathcal N(i)}\sum\limits_{m=1}^{M}\sum\limits_{n \in \mathcal N(i)}K_{\sigma}(\mathcal k_{m},x_{n}-x_{i}) \tag {1} $
$\mathcal k_{m}$表示kernel中的m个可学习的点,$\mathcal N(i)$ 表示anchor point $x_{i}$的周围K近邻,而$K_{\sigma}(*,*)$表示核函数,也就是公式$(2)$所示。公式$(1)$大体就是对于某个corelation kernel来说,其中每个点$\mathcal k_{m}$都会与$\mathcal N(i)$中包括的点一起作为公式$(1)$的输入,也就是会计算m*k次。
$K_{\sigma}(k,\delta) = exp(-\cfrac{||k-\delta||^2}{2\delta^2}) \tag {2}$
分子表示欧式距离,分母$\delta$表示核的宽度,它控制点之间距离的影响(这里我也不是太懂)。文中的$\delta$被设置为the average neighbor distance in the neighborhood graphs over all training point clouds。
可以设置$L$个kernel corelation,这个$L$与卷积网络中的output channel类似。
- Learning on Local Feature Structure
核心思想就是每个点预期近邻点的几何结构是一致,将各个点与其自身的近邻点做特征向量的aggregation有利于使得网络具有更好的效果和鲁棒性。作者采用了average pooling和max pooling, 其中max pooling为
$\mathcal Y(i,k) = \max\limits_{n \in \mathcal N(i)} X(n,k) \tag{3}$
k表示第i个点的特征向量的第k个维度,特征向量维度与kernel corelation的核数量一致
average pooling为:
$Y=D^{-1}WX \tag{4}$
$W$为邻接矩阵,$D$为度矩阵(degree matrix)
本文采用的是Max pooling作为Aggregation方法
- Experiment:
作者通过Ablation study从Effectiveness of Kernel Correlation,Symmetric Functions,Effectiveness of Local Structures三个方面证明了本文所提方法的有效性:
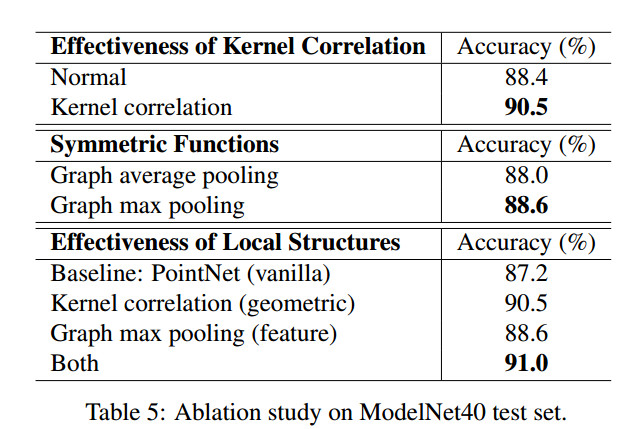
**但我觉得存在一个问题:**在Effectiveness of Kernel Correlation试验中,每个点的Normal是使用PCA方法求出的,然后再与坐标Catenate.那么所求的Normal与真实的值相差多少呢?这个误差是否会影响实验结果呢?如果改用更加准确的Normal求解方法,是否能提高,甚至超过Kernel Correlation方法呢?
Conclusion:####
这篇工作的根本目的在于探究一种较PointNet++更为简单的局部几何计算子,从而在节省算力的同时,还能提高准确度。但是其本质上是以一种更加简单的方式回答what type of the point,其没有解决点与点之间是什么关系,换句话说,PointNet++与KC-Net的本质与[1]中的DG-CNN是不同的,这可能也是造成他们效果差异的原因。
MeshNet: Mesh Neural Network for 3D Shape Representation
Description:####
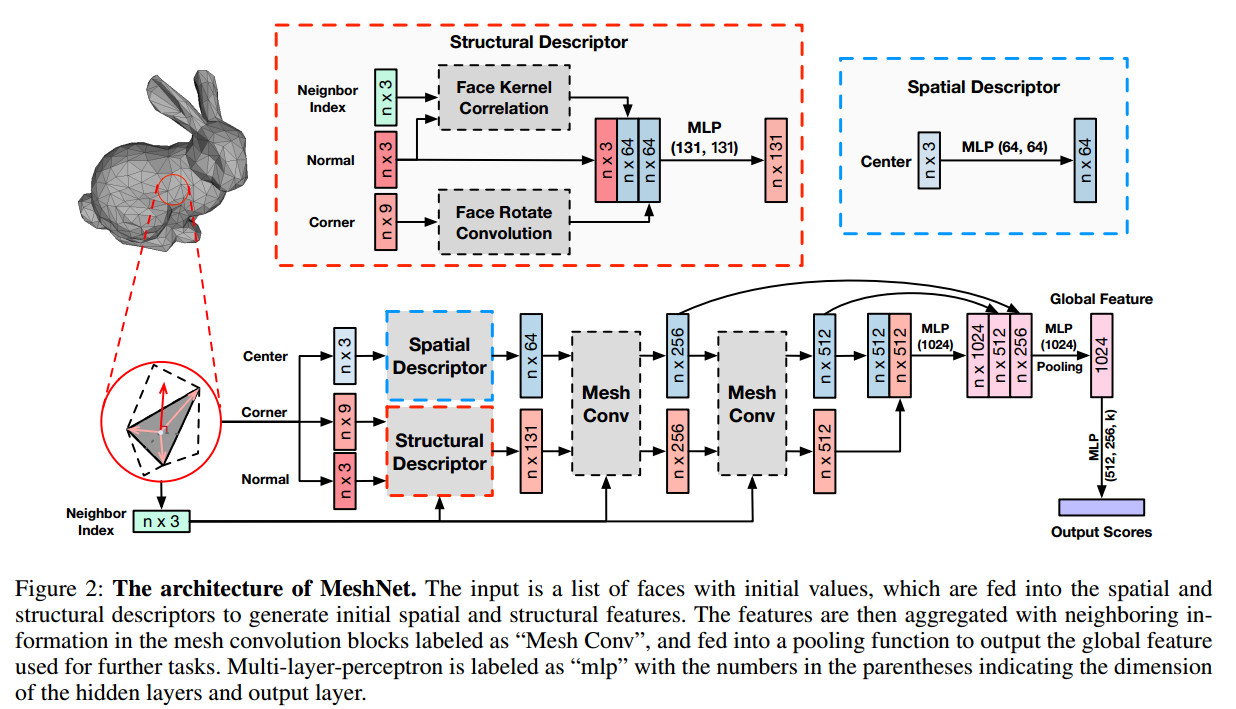
本文提出一种基于Mesh的3D shape特征抽取方法,直接将对于Mesh-based 3D shape的分类准确率从68.3%提升到91.9%。作者将单独的一个Face视为一个Unit,这样做可以消除Mesh固有的irregular,因为每一个face有且只有3个面与其相邻(作者这里用的是no more than,我认为不对)。其次,作者将一个Face的Feature分为spatial feature和structural feature,这样做有利于是Face Feature具有更加明确的指向性,使网络更容易学习到有用的Feature
Method:####
Input: 作者将
Face-unit进行了如下分解:Face Information:
- Center:coordinate of center point
- Corner:vectors from the center point to three vertices
- Normal: the unit normal vector
Neighbor Information:
- Neighbor Index: indexes of the connected faces(filled with the index of itself if the face connects with less than three faces) 如果面片形成的是一个闭集,那么必然是一个面片有三个相邻面的
Spatial and Structural Descriptor
spatial descriptor: 输入只是Center坐标,简单的经过MLP得到结果
Structural descriptor:face rotate convolution
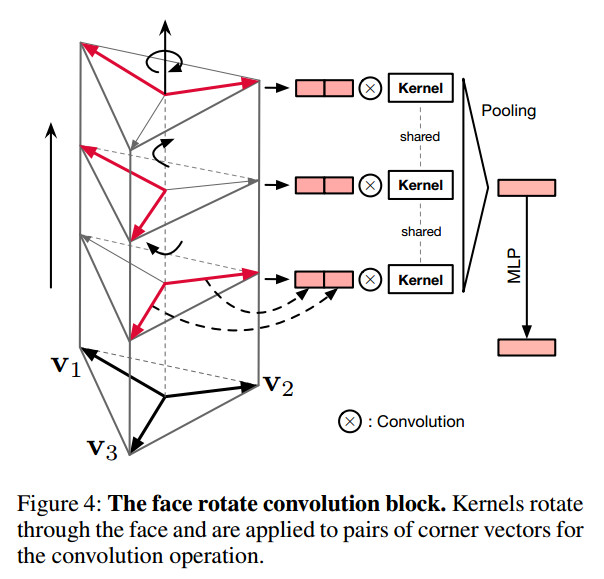
$g(\cfrac{1}{3}(f(v_{1},v_{2})+f(v_{2},v_{3})+f(v_{3},v_{1})) \tag{1}$
$f(*,*) : \mathbb R^3 * \mathbb R^3 \rightarrow \mathbb R^{K_1}$
$g(*,*) : \mathbb K^1 \rightarrow \mathbb K^2$可以是任何合法函数(大多都是MLP)
作者将这个操作类比到卷积操作,$f(*,*)$看作卷积核,每次对两个向量做卷积,然后用旋转代替平移,步长为1。$K_1$表示output channel。这个$\cfrac{1}{3}$可以当做对称函数(average pooling)用来消除disorder,保证了permutation invariance。
Structural descriptor: face kernel correlation:
作者利用[2]的kernel corelation将其改为针对face-unit的形式,利用面片的normal代替[2]中点的坐标。由于所有的normal都是单位向量所以作者用$(\theta,\phi)$ 来代替单位向量$(x,y,z)$ 所以有
$\begin{cases}
& x=sin \theta cos \phi \\
& y=sin \theta sin \phi \\
& z=cos \phi \tag{2} \\
\end{cases}$
其中:$\theta \in [0,\pi], \phi \in [0,2\pi)$(其实就是仰角和旋转角)
$KC(\mathcal k,x_{i} ) = \cfrac{1}{\mathcal |N(i)| \mathcal |M_k|)}\sum\limits_{n \in \mathcal N_i}\sum\limits_{m \in \mathcal M_k}K_{\sigma}(n,m) \tag {3} $
$K_{\sigma}(n,m) = exp(-\cfrac{||n-m||^2}{2\delta^2}) \tag {4}$
这些都与[2]中的含义一致
- Mesh Convolution
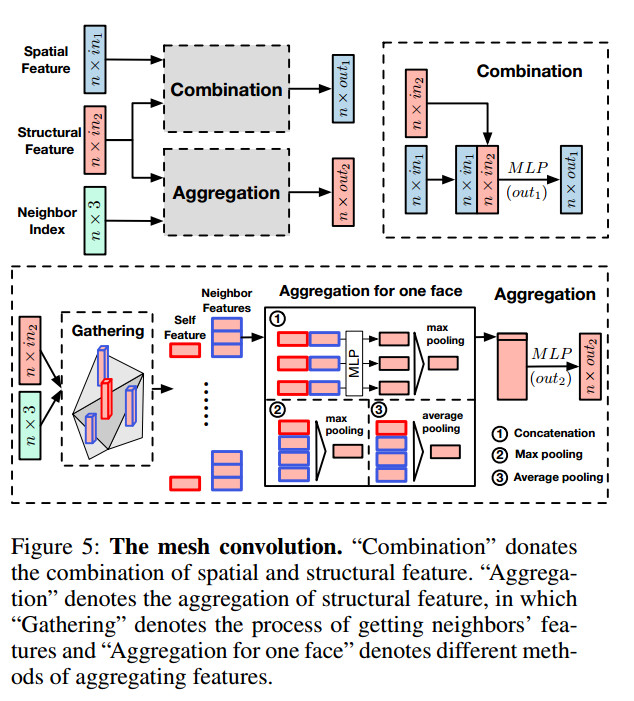
如图所示,作者将spatial Feature,structral Feature和Neighbor Index,作为输入送进Combination和Aggregation中,得到新的spatial Feature和structral Feature。 作者在文中提到,之所以不将spatial Feature一起送进Aggregation是因为不想让structral Feature受到点所在空间信息的影响,就如2维卷积的过程中,不会显示的告知卷积核该像素的绝对坐标一样。
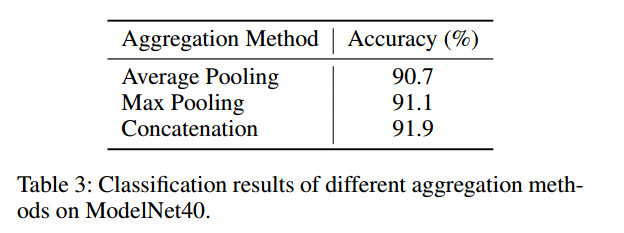
图中标识了三种Aggregation方法:Concatenation,Max pooling和Average pooling 作者认为Average pooling是很多强响应被忽略了,从而损失了很多的有用信息。实验表明Concatenation效果最好。
Conclusion:####
- 将Feature拆分为多个更加明确的子特征,可能有助于网络学习
- 本文有个缺点就是没有考虑显示的考虑面片之间的结构关系,每个面片的特征都只与其本身有关,但不排除在之后了MLP层之后学习到了。
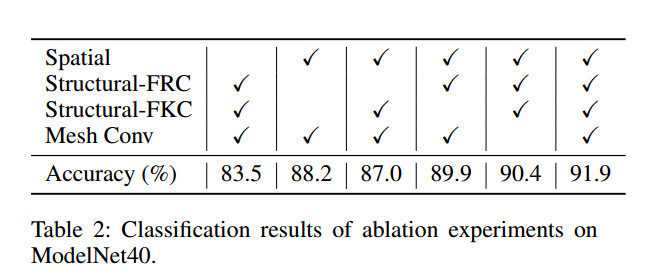
结果显示在移除了MeshConv之后,准确度下降的比重不是最大的
Structural Relational Reasoning of Point Clouds
Description####
作者首先阐述了Pointnet++的缺点,与[1]中提到的一致–只是探究了局部的结构特征,没有探究这些局部之间的结构也就是依赖关系。但是与[1]不同的是,本文所提出的structural relation network(SRN)探究的是局部与局部的依赖关系(structural
dependencies of local regions),而[1]是以点为单位的。作者以人类识别物体为例,认为对物体局部之间关系的认知对于理解物体本身具有很大作用
Method####
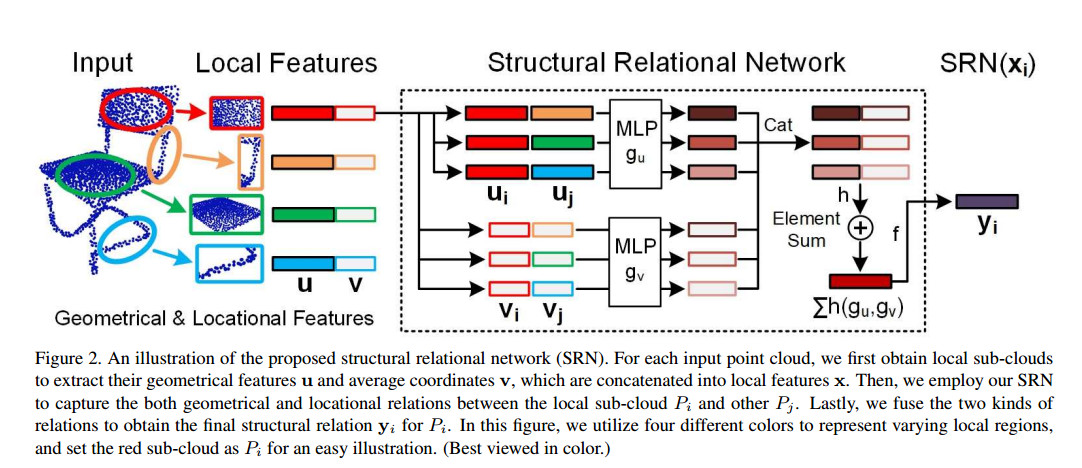
$P_i$代表子点云,$u_i \in \mathbb R^d$代表该子点云的局部几何特征,$v_i \in \mathbb R^3$表示该子点云的平均位置用来表示位置信息。作者认为$u_i$对发现重复的局部模式(repetitive local patterns)有帮助,而$u_i$对发现各个局部之间的连接关系(linkage relations)起到关键作用。所有$P_i$的结构关系特征表示为:
$y_i = f(\sum \limits_{\forall j}h(g_u(u_i,u_j),g_v(v_i,v_j)) \tag{1}$
$j$表示除了$i$以外的所有子点云。在实现方面,$g_u(·,·),g_v(·,·)$都是由多层感知机(MLP)实现,$f(·,·),h(·,·)$都是由1 $\times$ 1卷积实现。由上面那张图可以看出每个$u_i$都会与其他的所有$u_j$做一次concatenating操作(应该是在channel维度进行拼接)
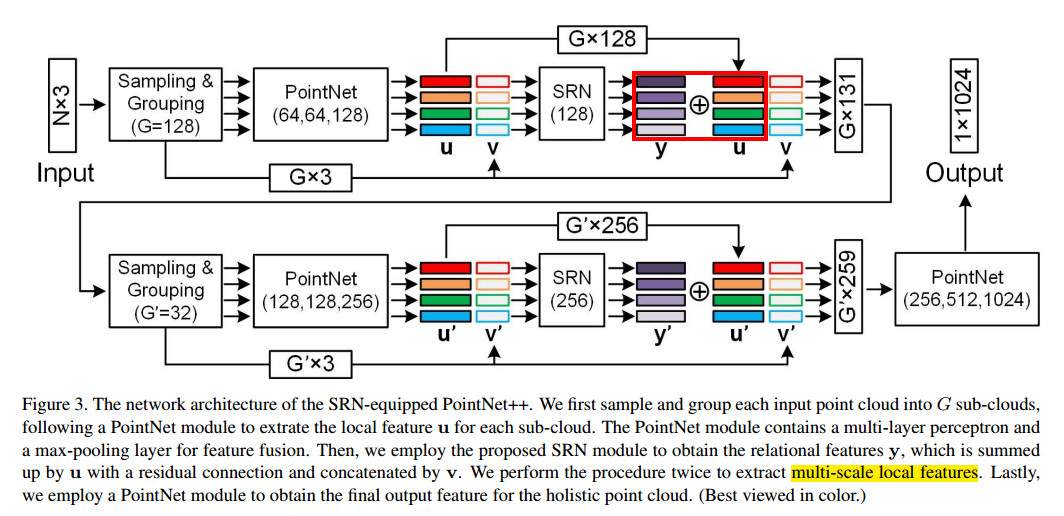
注意到标黄部分,采用了不同比例的局部特征,作者认为SRN对于不同的子点云获取方法都是鲁棒的。同时红框表示文中提到的residual connection$y$是作为对$u$的补充(complement)
Experiment####
为了证明SRN对3D Shape的局部关系学习具有很好的泛化性,作者在ModelNet40(3D objects)和Scannet(indoor scenes)上做了跨库实验
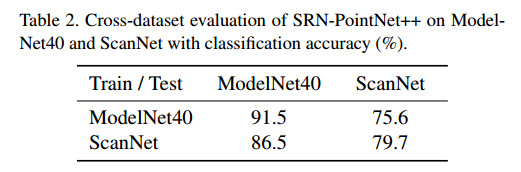
作者提取分布在两个库上训练的网络所产生的特征向量(feature)之后用线性SVM做分类
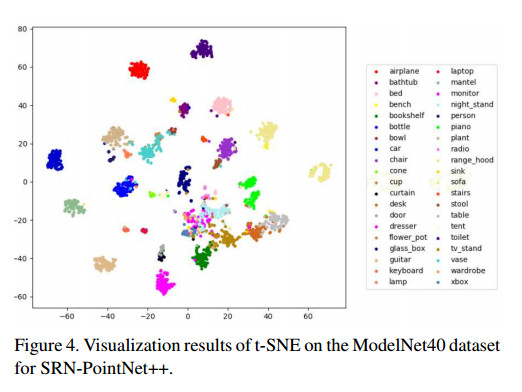
作者为了进一步阐述SRN对特征提取的帮助,利用t-SNE(一种对高维数据降维可视化的方法)将所提取的特征进行可视化。发现大多数类别的类间差异都很小。
Relation-Shape Convolutional Neural Network for Point Cloud Analysis
Description:####
作者依旧是从探究点与点之间的关系来入手,作者认为从点学习特征具有三点挑战:
- 需要具备排列不变性(permutation invariant)
- 对于刚性形变鲁棒,也就是即使点的绝对位置发生改变,只要其结构未变,其特征应该是一致的
- 效果好
Method####
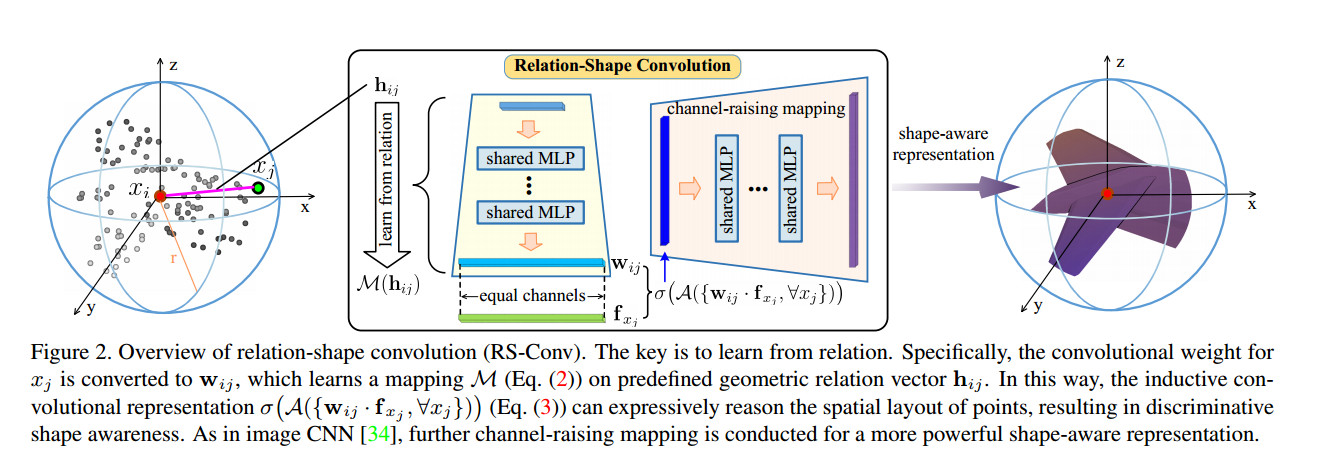
$x_i$表示采样点,$x_j \in \mathcal N(x_i)$表示周围邻域点,则该$x_i$上的特征向量$f_{P_{sub}}$可以用来表示这个邻域的结构
$f_{P_{sub}} = \sigma(\mathcal A(\lbrace \tau(f_{x_j}), \forall x_j \rbrace)), d_{ij} <r \forall x_j \in \mathcal N(x_i) \tag{1}$
$\tau(f_{x_j}) = w_{ij} · f_{x_j} = \mathcal M(h_{ij} · f_{x_j}) \tag{2}$
$d_{ij}$是$x_i,x_j$之间的欧式距离。对于上面这个公式,论文的解释是:Here $f_{P_{sub}}$ is obtained by first transforming the features of all the points in $\mathcal N(i)$ with function $\tau$ , and then aggregating them with function $\mathcal A$ followed by a nonlinear activator $\sigma$.
公式(1)相对于论文[1]多了一个$\tau$函数,其余操作一致,$\mathcal A$也是max pooling $\mathcal M$为三层MLP作者之后在试验中证明了3层是较好的选择
Conclusion####
这篇文章是被录用为CVPR2019的oral.但是其最核心的思想我认为跟[1]是差不多的,作者在文中也用一句话评价了两者的区别DGCNN captures similar local shapes by learning point relation in a high-dimensional feature space, yet this relation could be unreliable in some cases. 我刚看到简直吐血,真·不要碧莲。我认为之所以能被接受为oral原因如下:
- 优秀的写作,论文从问题到解决办法的提出一气呵成,非常漂亮,很多地方的写作技巧都很微妙,比如上面这句。
- 实验做得很充分,几乎论证了所有文中提出的tricks。同时效果确实有不小的提升。
- 具体用到的tricks如下:
- 利用了
hierarchical architecture,在相同的权重下,对不同数量的neighborhoods进行学习,这与[4]是一致的,但文中没有提出这点 - $\tau$函数的提出,新学习到的特征向量与老的特征向量做一次点乘,这与ICML2019GEOMetrics: Exploiting Geometric Structure for Graph-Encoded Objects类似。
- 相对[1]对每个点求其邻域的特征向量,本文对每个选取的领域求特征
- 论文采取的对邻域的选取方法也与其他不相同
 可以看到,在scale=1的情况下,用
可以看到,在scale=1的情况下,用K-NN选取邻域只有90.5%的准确率,而转为random-PIB之后就提升到了92.2%,这与DGCNN对每个点都求一个结构特征所得到的准确率是一致,但计算量却大大减少了
- 利用了
很可惜,对于核心方法的修改,作者没有给出消融实验的结果,不能看出新增的$\tau$函数对效果的提升有什么帮助。同时对于输入h是否会变也没有给出明确的说明,就符号一致性来说,是不会改变的,[1]中是会改变的